Machine Learning Framework
Congratulations on your second day, it seems like the co-workers are impressed with you. They told that you talked to them about what machine learning is and they were impressed with the amount of knowledge. So good job. But anyway, we got to get you working because we have a lot of clients and they really need us. So we have a client right now that needs to implement their own machine learning data science framework for their employees. They have about 20 data scientists, 20 machine learning engineers, and everybody’s kind of doing their own thing. We need a way to standardize their practices into one so that they can manage all their employees. Would you mind creating a framework that our clients can use and maybe we can use at our company as well?
Keiko Corp. needs something standardized so that when we hire more people like you were able to have a nice, clear framework that they can use. Shouldn’t be a problem for you, right, genius?
Well, it’s time to ask our friend the creators.
So in this section, we’re going to build our own machine learning and data science framework. That is a template that we can use throughout the rest of the course, throughout the rest of your career to think about how to solve problems. Let’s create our own framework. And hopefully going to work the next day and make Bruno happy once again, survive day to. Let’s get started.
Introducing Framework
Now, if you’ve looked up machine learning before, you know, there’s a lot out there, some resources recommend learning mathematics, statistics, probability and even more before getting started with data science and machine learning. And while these topics, they’re important, trying to learn them all before getting started, getting hands on is like trying to boil the ocean. Instead, what we’re going to be doing is focusing on building practical solutions and writing machine learning code to get insights out of data.
Machine learning comes in three parts data collection, data modeling and deployment. You might take this machine learning model and deploy it to to users through your application or through an API or some sort. We’re going to cover data modeling, which means you’ll be able to take a data set and apply machine learning algorithms to find insights on that data. Instead of doing anything and everything from scratch, we’re going to be using what works to build practical solutions and at the same time learning about machine learning and data science. Now let’s take a deeper look at the framework we’re going to be using.
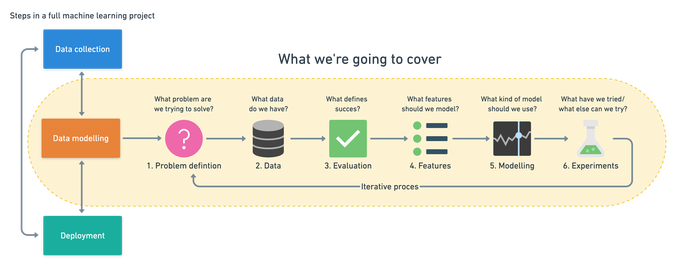
6 Step machine learning framework
A machine learning pipeline can be broken down into three major steps. Data collection, data modelling and deployment. All influence one another. You may start a project by collecting data, model it, realise the data you collected was poor, go back to collecting data, model it again, find a good model, deploy it, find it doesn’t work, make another model, deploy it, find it doesn’t work again, go back to data collection. It’s a cycle. Let’s break down how you might approach it :
-
Problem definition - What business problem are we trying to solve? How can it be phrased as a machine learning problem?
-
Data - If machine learning is getting insights out of data, what data we have? How does it match the problem definition? Is our data structured or unstructured? Static or streaming?
-
Evaluation - What defines success? Is a 95% accurate machine learning model good enough?
-
Features - What parts of our data are we going to use for our model? How can what we already know influence this?
-
Modelling - Which model should you choose? How can you improve it? How do you compare it with other models?
-
Experimentation - What else could we try? Does our deployed model do as we expected? How do the other steps change based on what we’ve found?
Problem Definition
To help decide whether or not your business could use machine learning, the first step is to match the business problem you’re trying to solve a machine learning problem. The four major types of machine learning are supervised learning, unsupervised learning, transfer learning and reinforcement learning.
-
Supervised Learning - Supervised learning, is called supervised because you have data and labels. A machine learning algorithm tries to learn what patterns in the data lead to the labels. The supervised part happens during training. If the algorithm guesses a wrong label, it tries to correct itself. It’s important to remember this prediction isn’t certain. It comes back as a probability. The algorithm says, “based on what I’ve seen before, it looks like this new patients medical records are 70% aligned to those who have heart disease.”
-
Unsupervised Learning - Unsupervised learning is when you have data but no labels. The data could be the purchase history of your online video game store customers. Using this data, you may want to group similar customers together so you can offer them specialised deals. You could use a machine learning algorithm to group your customers by purchase history. After inspecting the groups, you provide the labels. There may be a group interested in computer games, another group who prefer console games and another which only buy discounted older games. This is called clustering.
-
Transfer Learning - Transfer learning is when you take the information an existing machine learning model has learned and adjust it to your own problem. Training a machine learning model from scratch can be expensive and time-consuming. The good news is, you don’t always have to. When machine learning algorithms find patterns in one kind of data, these patterns can be used in another type of data.
If machine learning can be used in your business, it’s likely it’ll fall under one of these three types of learning. But let’s break them down further into classification, regression and recommendation.
-
Classification - Do you want to predict whether something is one thing or another? Such as whether a customer will churn or not churn? Or whether a patient has heart disease or not? Note, there can be more than two things. Two classes is called binary classification, more than two classes is called multi-class classification. Multi-label is when an item can belong to more than one class.
-
Regression - Do you want to predict a specific number of something? Such as how much a house will sell for? Or how many customers will visit your site next month?
-
Recommendation - Do you want to recommend something to someone? Such as products to buy based on their previous purchases? Or articles to read based on their reading history?
Data
The data you have or need to collect will depend on the problem you want to solve. If you already have data, it’s likely it will be in one of two forms. Structured or unstructured. Within each of these, you have static or streaming data.
-
Structured data - Think a table of rows and columns, an Excel spreadsheet of customer transactions, a database of patient records. Columns can be numerical, such as average heart rate, categorical, such as sex, or ordinal, such as chest pain intensity.
-
Unstructured data - Anything not immediately able to be put into row and column format, images, audio files, natural language text.
-
Static data - Existing historical data which is unlikely to change. Your companies customer purchase history is a good example.
-
Streaming data - Data which is constantly updated, older records may be changed, newer records are constantly being added.
The principle remains. You want to use the data you have to gains insights or predict something. For supervised learning, this involves using the feature variable(s) to predict the target variable(s). A feature variable for predicting heart disease could be sex with the target variable being whether or not the patient has heart disease. For unsupervised learning, you won’t have labels. But you’ll still want to find patterns. Meaning, grouping together similar samples and finding samples which are outliers. For transfer learning, your problem stays a supervised learning problem, except you’re leveraging the patterns machine learning algorithms have learned from other data sources separate from your own.
Evaluation
You’ve defined your business problem in machine learning terms and you have data. Now define what defines success. There are different evaluation metrics for classification, regression and recommendation problems. Which one you choose will depend on your goal. Some things you should take into consideration for classification problems :
-
False negatives - Model predicts negative, actually positive. In some cases, like email spam prediction, false negatives aren’t too much to worry about. But if a self-driving cars computer vision system predicts no pedestrian when there was one, this is not good.
-
False positives - Model predicts positive, actually negative. Predicting someone has heart disease when they don’t, might seem okay. Better to be safe right? Not if it negatively affects the person’s lifestyle or sets them on a treatment plan they don’t need.
-
True negatives - Model predicts negative, actually negative. This is good.
-
True positives - Model predicts positive, actually positive. This is good.
-
Precision - What proportion of positive predictions were actually correct? A model that produces no false positives has a precision of 1.0.
-
Recall - What proportion of actual positives were predicted correctly? A model that produces no false negatives has a recall of 1.0.
-
F1 score - A combination of precision and recall. The closer to 1.0, the better.
-
Receiver operating characteristic (ROC) curve & Area under the curve (AUC) - The ROC curve is a plot comparing true positive and false positive rate. The AUC metric is the area under the ROC curve. A model whose predictions are 100% wrong has an AUC of 0.0, one whose predictions are 100% right has an AUC of 1.0.
For regression problems (where you want to predict a number), you’ll want to minimise the difference between what your model predicts and what the actual value is. If you’re trying to predict the price a house will sell for, you’ll want your model to get as close as possible to the actual price. To do this, use MAE or RMSE :
-
Mean absolute error (MAE) - The average difference between your model’s predictions and the actual numbers.
-
Root mean square error (RMSE) - The square root of the average of squared differences between your model’s predictions and the actual numbers.
Recommendation problems are harder to test in experimentation. One way to do so is to take a portion of your data and hide it away. When your model is built, use it to predict recommendations for the hidden data and see how it lines up.
Features
Not all data is the same. And when you hear someone referring to features, they’re referring to different kinds of data within data. The three main types of features are categorical, continuous (or numerical) and derived.
-
Categorical features - One or the other(s). For example, in our heart disease problem, the sex of the patient. Or for an online store, whether or not someone has made a purchase or not.
-
Continuous (or numerical) features - A numerical value such as average heart rate or the number of times logged in.
-
Derived features - Features you create from the data. Often referred to as feature engineering. Feature engineering is how a subject matter expert takes their knowledge and encodes it into the data. You might combine the number of times logged in with timestamps to make a feature called time since last login. Or turn dates from numbers into “is a weekday (yes)” and “is a weekday (no)”.
Text, images and almost anything you can imagine can also be a feature. Regardless, they all get turned into numbers before a machine learning algorithm can model them. Some important things to remember when it comes to features :
-
Keep them the same during experimentation (training) and production (testing) - A machine learning model should be trained on features which represent as close as possible to what it will be used for in a real system.
-
Work with subject matter experts - What do you already know about the problem, how can that influence what features you use? Let your machine learning engineers and data scientists know this.
-
Are they worth it? - If only 10% of your samples have a feature, is it worth incorporating it in a model? Have a preference for features with the most coverage. The ones where lots of samples have data for.
-
Perfect equals broken - If your model is achieving perfect performance, you’ve likely got feature leakage somewhere. Which means the data your model has trained on is being used to test it. No model is perfect.
Modelling
Before we get into these, though, part one of modeling is and the most paramount topic to discuss in this whole entire section is the most important concept in machine learning, the train validation and test splits or commonly referred to as three sets. Now, since you want to be using machine learning models to gain insights on some data to predict the future, it’s important to test how well they would go and do in the real world. To do this, you split your data into three different sets, a training set to train your model on a validation set to choose your model on, and a test set to test and compare your different models.
Why is this important? The ability for a machine learning model to perform well on data it hasn’t seen before because of what it’s learned on another dataset. This is where training, validation and test splits come in.
In our heart disease example, let’s say there were 100 patients. We start off with one hundred. One way to create the splits is to shuffle these patients, then select 70 percent for training. Which would mean that would be about 70 patient records and 15 per cent for validation and 15 per cent for testing, which means about 70 patients in the training set 15 patients and the validation split and 15 patients in the test split. Now, the percentages of each of these may vary, but standard practice is usually around 70 to 80 percent for training, 10 to 15 for validation and 10 15 for test. You may see in some examples that some sets or some data sets only gets split into training and test. But that’s case by case scenario.
Usually you’ll have three different sets. What’s important to remember is that all three of these sets a separate during training, the model never sees a validation split or the test split. And during testing, you’re doing it on the test split, not the training set.
Once you’ve defined your problem, prepared your data, evaluation criteria and features it’s time to model. Modelling breaks into three parts, choosing a model, improving a model, comparing it with others.
- Choosing a model
When choosing a model, you’ll want to take into consideration, interpretability and ease to debug, amount of data, training and prediction limitations. To address these, start simple. A state of the art model can be tempting to reach for. But if it requires 10x the compute resources to train and prediction times are 5x longer for a 2% boost in your evaluation metric, it might not be the best choice. Linear models such as logistic regression are usually easier to interpret, are very fast for training and predict faster than deeper models such as neural networks.
- Tuning a model
A model’s first results isn’t its last. Like tuning a car, machine learning models can be tuned to improve performance. Tuning a model involves changing hyperparameters such as learning rate or optimizer. Or model-specific architecture factors such as number of trees for random forests and number of and type of layers for neural networks. The priority for tuning and improving models should be reproducibility and efficiency. Someone should be able to reproduce the steps you’ve taken to improve performance. And because your main bottleneck will be model training time, not new ideas to improve, your efforts should be dedicated towards efficiency.
- Comparing models
Since your model has never seen data in the test set, evaluating your model on it is a good way to see how it generalizes. A good model will yield similar results on the training, validation and test sets, and it’s not uncommon to see a slight decline in performance from the model. On the training and validation set to the test set, for example, your model might achieve 98 per cent accuracy on the training dataset and 96 percent accuracy on the test set. What you should be worried about is if the training set performance is dramatically higher than the test set, also known as underfitting, and if the test set performance is higher than the training set performance, also known as OVERFITTING. The ideal model shows up in the Goldilocks zone. It fits just right, not too well, but not too poorly.
Now, there are several reasons why underfitting an opening can happen, but the main ones are data leakage and data mismatch. Data leakage happens when some of your test data leaks into your training data, and this often results in overfitting or a model doing better on the test set than on the training data said. Data mismatch happens when the data you’re testing on is different to the data you’re training on, such as having different features in the training data to the test data. Having this kind of mismatch can lead to models performing poorly on test data compared to training.
Other ways to combat underfeeding include using a more advanced model, this could mean a totally different model or increasing the number of hyper parameters on your current model. You could also reduce the number of features you’re trying to model, maybe your data has too many features and the model you’re using is struggling to find patterns in them. Finally, you could train your model for longer, sometimes models take longer to train or longer to learn than you’d expect.
And to reduce overfitting, useful solutions are to collect more data, more data will provide more potential patterns for a model to find and thus lower the potential for it to find them all. Or you could try use a less advanced model. This is uncommon, but it’s a possibility.
Finally, when comparing two different models to each other, it’s important to ensure you’re comparing apples with apples and oranges with oranges. For example, model two trained on dataset 1 versus model three, trained on dataset 1. Enduring comparison, you want to make sure you take into account not only the final result, but what it took to get there. If Model two takes one second to make a prediction at 93.1% accuracy, model three takes four seconds to make a prediction at 94.7% accuracy. Is that an extra three percent accuracy worth that extra three seconds of prediction?
Experimentation
This step involves all the other steps. Because machine learning is a highly iterative process, you’ll want to make sure your experiments are actionable. Your biggest goal should be minimising the time between offline experiments and online experiments. Offline experiments are steps you take when your project isn’t customer-facing yet. Online experiments happen when your machine learning model is in production. All experiments should be conducted on different portions of your data.
Poor performance on training data means the model hasn’t learned properly. Try a different model, improve the existing one, collect more data, collect better data. Poor performance on test data means your model doesn’t generalise well. Your model may be overfitting the training data. Use a simpler model or collect more data. Poor performance once deployed (in the real world) means there’s a difference in what you trained and tested your model on and what is actually happening.
Tools Used
To do this will use Anaconda, which is like the hardware store of data science and machine learning tools. And then once you’ve got Anaconda getting all of these other machine learning tools like Jupyter notebook, PyCharm, matplotlib, pandas, Scikit learn, cat boost, XGboost and TensorFlow. Some of these are a mouthful, but once you’ve got anaconda getting these tools that we need to to apply to that process we’ve just created, that framework we’ve created will be an absolute breeze.
So for data analysis, you’ll be using things like pandas, matplotlib and numpy. For building machine learning models, you use things like TensorFlow, PyTorch, Scikit learn, XGboost and cat boost. And what’s important to remember is your most important role will not be knowing all of the functions of each of these single libraries off by heart. It will be knowing which tool to use for what kind of problem.