The Machine Learning Landscape
What is Machine Learning?
Machine Learning is the science of programming computers so they can learn from data. Some general definitions :
It is the field of study that gives computers the ability to learn without being explicitly programmed. - Arthur Samuel, 1959
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. - Tom Mitchell, 1997
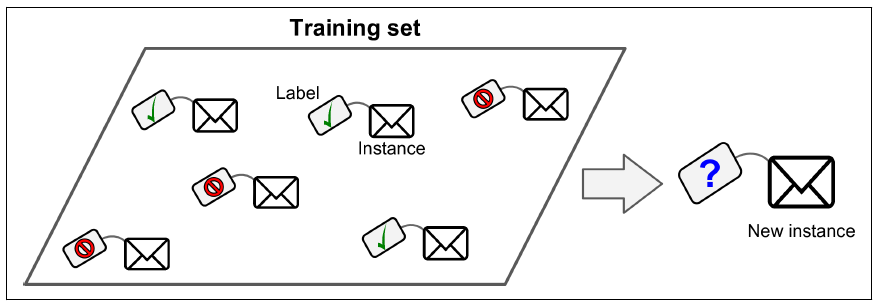
Spam filter program is an example of Machine Learning program. It uses example emails to learn if its spam or not. The examples that the system uses to learn are called training set. Each training example is called training instance. In this case the task T is to flag spam for new emails, the experience E is the training data and performance measure P is the accuracy by which it is assigning emails as spam.
Why use Machine Learning?
First lets see how we would write the spam filter program with traditional programming :
- First we need to find what typically looks like spam. Like - words, sender’s name etc.
- Then we would have to write a detection algorithm for each pattern that we noticed, and our program would flag emails as spam if pattern detected.
- We need to repeat above steps until it is good enough to launch.
Now if we would have used Machine Learning techniques our program would have automatically learned the words to identify if a email is spam or not. These programs are much shorter, easier to maintain and most likely more accurate. Moreover they get updated automatically without manual interventaion. Another area where machine learning shines is for the problems that either are too complex for traditional approach or have no known algorithm. For eg. Speech recognition. Finally, Machine Learning can help humans learn. For eg. once machine learning learns about which email is spam or not, that list can be provided to humans.
Applying ML techniques to dig into large amounts of data can help discover patterns that were not immediately apparent. This is called data mining. To summarize machine learning is great for :
- Problems for which existing solution require a lot of fine tuning.
- Complex problems for which traditional approach yields no solution.
- Fluctuating environments.
- Getting insights about complex problems.
Examples of Machine Learning
- Analyzing images of products on a production line to automatically classify them.
- Detecting tumors in brain scans
- Automatically classifying news articles.
- Automatically flagging offensive comments on discussion forums.
- Summarizing long documents automatically.
- Detecting credit card fraud.
- Building an intelligent bot for a game.
Types of Machine Learning systems
Generally systems are classified into 3 broad categories :
- If trained under human supervision or not.
- If they can learn on the fly.
- Simple compare or detecting patterns.
Supervised Learning
In this the training set we feed to algorithm also includes the desired solutions called labels. A typical supervised learning task is classification (Spam filter).
Another typical task is predicting a target numerical value called regression (Price of car). Note that some of the regression problems can be used for classification as well and vice versa. Some important supervised algorithms :
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machine
- Decision trees and Random Forests
- Neural networks
Unsupervised Learning
In this the training data is unlabeled. The system tries to learn without a teacher.
Some of the most important unsupervised learning algorithms :
- Clustering
- K-Means
- DBSCAN
- Hierarchical Cluster Analysis (HCA)
- Anomaly detection and novelty detection
- One-class SVM
- Isolation Forest
- Visualization and dimensionality reduction
- Principal Component Analysis (PCA)
- Kernel PCA
- Locally Linear Embedding (LLE)
- t-Distributed Stochastic Neighbor Embedding (t-SNE)
- Association rule learning
- Apriori
- Eclat
Eg. - If we have alot of data about our blog’s visitor. We may want to run a clustering algorithm to try to detect groups of similar visitors. At no point we tell the system which visitor belongs to which category. The system tries to find it automatically. In Visualization algorithms we feed a lot of complex data and they give output a 2D or 3D representation of our data.
-
A related task is dimensionality reduction, in which we simplify the data without losing too much information. One way it can be done by merging two or more features. For eg. - Car age and mileage can be merged into wear and tear. This is also called feature extraction.
-
Another common task is anomaly detection, for example, detecting unusual credit card transactions to prevent fraud, catching manufacturing defects, or automatically removing outliers from a dataset before feeding it to another learning algorithm. The system is shown mostly normal instances during training, so it learns to recognize them and when it sees a new instance it can tell whether it looks like a normal one or whether it is likely an anomaly.
-
Another common task is association rule learning, in which the goal is to dig into large amounts of data and discover interesting relations between attributes.
Semisupervised Learning
Since labeling data is usually time consuming and costly. Some algorithms can deal with data that is partially labelled. This is called semisupervised learning. For eg. - Google photos. Once you upload pictures and tag one person in one picture it automatically recognizes that same person is shown in other photos as well.
Reinforcement Learning
The learning system called an agent in this context can observe the environment select and perform actions and get rewards/penalties in return. It must then learn by itself what is best strategy called policy. A policy defines what action the agent should choose when it is in a given situation.
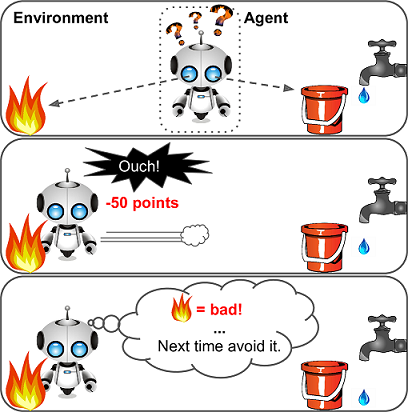
DeepMind’s AlphaGo program is also a good example of Reinforcement Learning: it made the headlines in May 2017 when it beat the world champion Ke Jie at the game of Go. It learned its winning policy by analyzing millions of games, and then playing many games against itself.
Batch Learning
In batch learning, the system is incapable of learning incrementally: it must be trained using all the available data. First the system is trained, and then it is launched into production and runs without learning anymore; it just applies what it has learned. This is called offline learning. If you want a batch learning system to know about new data, you need to train a new version of the system from scratch on the full dataset, then stop the old system and replace it with the new one.
This solution is simple and often works fine, but training using the full set of data can take many hours. Also, training on the full set of data requires a lot of computing resources.
Online learning
In online learning, you train the system incrementally by feeding it data instances sequentially, either individually or by small groups called mini-batches. Each learning step is fast and cheap, so the system can learn about new data on the fly, as it arrives
Online learning is great for systems that receive data as continous flow, have limited computational resources, have huge datasets that cannot fit in machine memory. One important parameter of online learning systems is how fast they should adapt to changing data: this is called the learning rate. If you set a high learning rate, then your system will rapidly adapt to new data, but it will also tend to quickly forget the old data. Conversely, if you set a low learning rate, the system will have more inertia; that is, it will learn more slowly, but it will also be less sensitive to noise in the new data or to sequences of nonrepresentative data points.
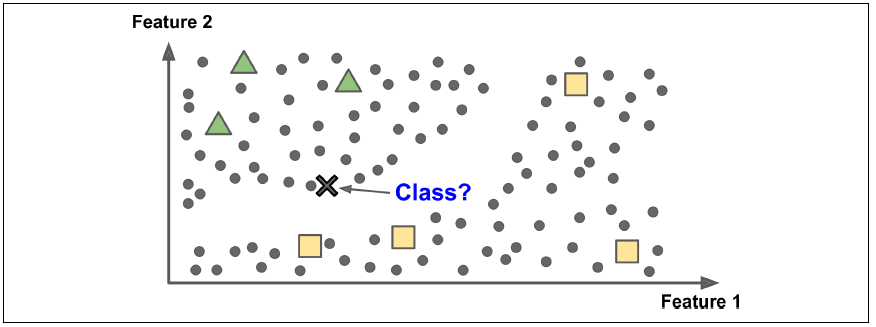
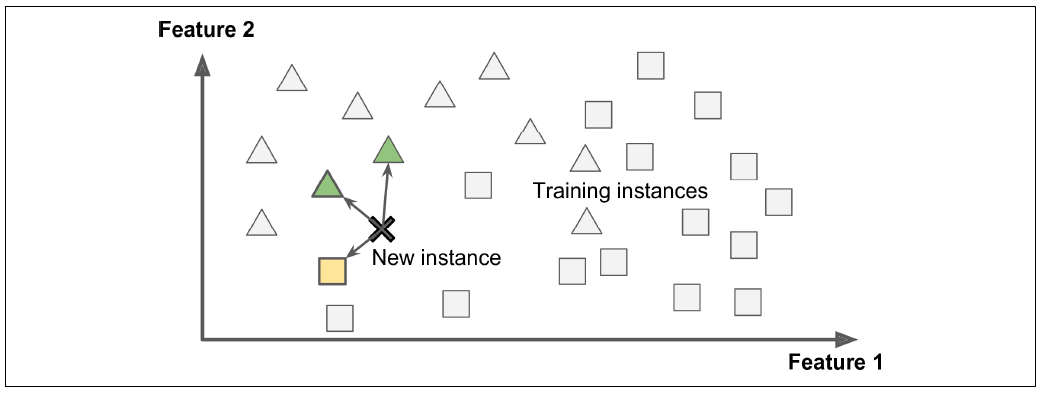
Instance-based learning
The system learns the examples by heart, then generalizes to new cases by comparing them to the learned examples (or a subset of them), using a similarity measure. For example, in the new instance would be classified as a triangle because the majority of the most similar instances belong to that class.
Model-based learning
Another way to generalize from a set of examples is to build a model of these examples, then use that model to make predictions. This is called model-based learning.
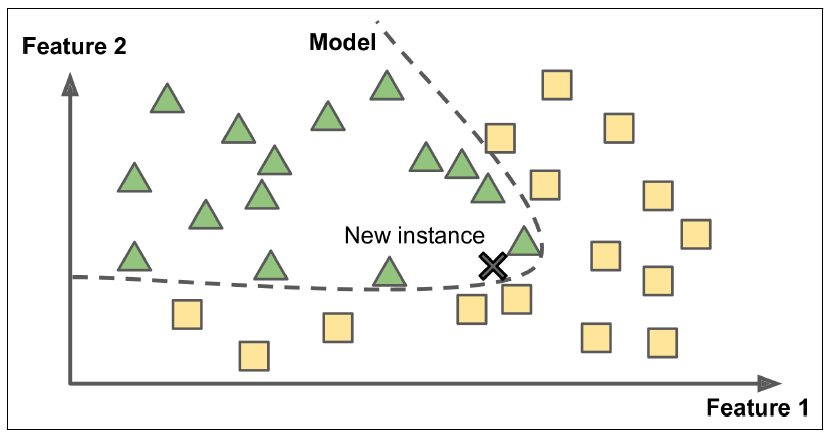
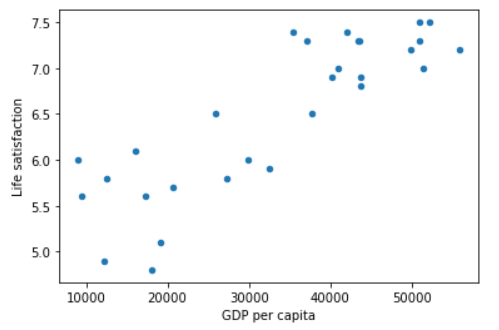
For example, suppose you want to know if money makes people happy, so you download the Better Life Index data from the OECD’s website as well as stats about GDP per capita from the IMF’s website. Then you join the tables and sort by GDP per capita. There does seem to be a trend here! it looks like life satisfaction goes up more or less linearly as the country’s GDP per capita increases. So you decide to model life satisfaction as a linear function of GDP per capita. This step is called model selection: you selected a linear model of life satisfaction with just one attribute, GDP per capita.
life_satisfaction = θ0 + θ1 X GDP_per_capita
Before you can use your model, you need to define the parameter values θ0 and θ1. How can you know which values will make your model perform best? To answer this question, you need to specify a performance measure. You can either define a utility function (or fitness function) that measures how good your model is, or you can define a cost function that measures how bad it is.
This is where the Linear Regression algorithm comes in: you feed it your training examples and it finds the parameters that make the linear model fit best to your data. This is called training the model. In our case the algorithm finds that the optimal parameter values are θ0 = 4.85 and θ1 = 4.91 × 10–5.
Python code that loads the data, prepares it, creates a scatterplot for visualization, and then trains a linear model and makes a prediction.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn.linear_model
# Merges the OCED's life satisfaction data and the IMF's GDP per capita data
def prepare_country_stats(oecd_bli, gdp_per_capita):
oecd_bli = oecd_bli[oecd_bli["INEQUALITY"]=="TOT"]
oecd_bli = oecd_bli.pivot(index="Country", columns="Indicator", values="Value")
gdp_per_capita.rename(columns={"2015": "GDP per capita"}, inplace=True)
gdp_per_capita.set_index("Country", inplace=True)
full_country_stats = pd.merge(left=oecd_bli, right=gdp_per_capita,left_index=True, right_index=True)
full_country_stats.sort_values(by="GDP per capita", inplace=True)
remove_indices = [0, 1, 6, 8, 33, 34, 35]
keep_indices = list(set(range(36)) - set(remove_indices))
return full_country_stats[["GDP per capita", 'Life satisfaction']].iloc[keep_indices]
# Load the data
oecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter='\t',encoding='latin1', na_values="n/a")
# Prepare the data
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# Visualize the data
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()
# Select a linear model
model = sklearn.linear_model.LinearRegression()
# Train the model
model.fit(X, y)
# Make a prediction for Cyprus
X_new = [[22587]] # Cyprus' GDP per capita
print(model.predict(X_new)) # outputs [[ 5.96242338]]
5.96242338
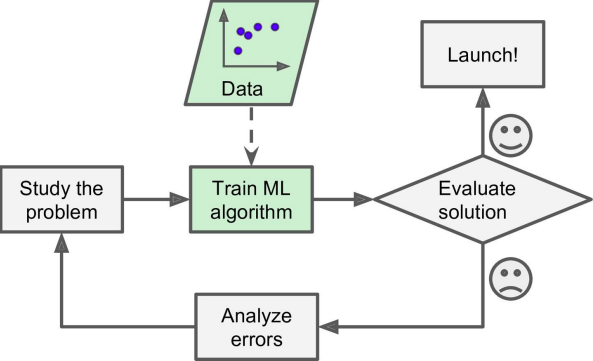
In summary :
- You studied the data.
- You selected a model.
- You trained it on the training data (i.e., the learning algorithm searched for the model parameter values that minimize a cost function).
- Finally, you applied the model to make predictions on new cases, hoping that this model will generalize well. This is what a typical Machine Learning project looks like.
Main challenges of Machine Learning
Insufficient Quantity of Training Data
It takes a lot of data for most Machine Learning algorithms to work properly. Even for very simple problems you typically need thousands of examples, and for complex problems such as image or speech recognition you may need millions of examples.
Nonrepresentative Training Data
In order to generalize well, it is crucial that your training data be representative of the new cases you want to generalize to. This is true whether you use instance-based learning or model-based learning. This is often harder than it sounds : if the sample is too small, you will have sampling noise (i.e., nonrepresentative data as a result of chance), but even very large samples can be nonrepresentative if the sampling method is flawed. This is called sampling bias.
Poor-Quality Data
Obviously, if your training data is full of errors, outliers, and noise (e.g., due to poorquality measurements), it will make it harder for the system to detect the underlying patterns, so your system is less likely to perform well. It is often well worth the effort to spend time cleaning up your training data. The truth is, most data scientists spend a significant part of their time doing just that.
Irrelevant Features
Your system will only be capable of learning if the training data contains enough relevant features and not too many irrelevant ones. A critical part of the success of a Machine Learning project is coming up with a good set of features to train on. This process, called feature engineering, involves :
- Feature selection: selecting the most useful features to train on among existing features.
- Feature extraction: combining existing features to produce a more useful one.
- Creating new features by gathering new data.
Overfitting the Training Data
Overgeneralizing is something that we humans do all too often, and unfortunately machines can fall into the same trap if we are not careful. In Machine Learning this is called overfitting : it means that the model performs well on the training data, but it does not generalize well. Complex models such as deep neural networks can detect subtle patterns in the data, but if the training set is noisy, or if it is too small, then the model is likely to detect patterns in the noise itself. Obviously these patterns will not generalize to new instances. The possible solutions are :
- To simplify the model by selecting one with fewer parameters, by reducing the number of attributes in the training data or by constraining the model
- To gather more training data
- To reduce the noise in the training data
Constraining a model to make it simpler and reduce the risk of overfitting is called regularization. For example, the linear model we defined earlier has two parameters, θ0 and θ1. This gives the learning algorithm two degrees of freedom to adapt the model to the training data: it can tweak both the height (θ0) and the slope (θ1) of the line. The amount of regularization to apply during learning can be controlled by a hyperparameter. A hyperparameter is a parameter of a learning algorithm (not of the model). As such, it is not affected by the learning algorithm itself; it must be set prior to training and remains constant during training. Tuning hyperparameters is an important part of building a Machine Learning system.
Underfitting the Training Data
Underfitting is the opposite of overfitting : it occurs when your model is too simple to learn the underlying structure of the data. For example, a linear model of life satisfaction is prone to underfit; reality is just more complex than the model, so its predictions are bound to be inaccurate, even on the training examples. The main options to fix this problem are :
- Selecting a more powerful model, with more parameters
- Feeding better features to the learning algorithm (feature engineering)
- Reducing the constraints on the model (e.g., reducing the regularization hyperparameter)
Testing and Validating
The only way to know how well a model will generalize to new cases is to actually try it out on new cases. This is done by splitting your data into two sets: the training set and the test set. As these names imply, you train your model using the training set, and you test it using the test set. The error rate on new cases is called the generalization error. If the training error is low but the generalization error is high, it means that your model is overfitting the training data.
Hyperparameter Tuning and Model Selection
So evaluating a model is simple enough: just use a test set. Now suppose you are hesitating between two models (say a linear model and a polynomial model): how can you decide? A common solution to this problem is called holdout validation: you simply hold out part of the training set to evaluate several candidate models and select the best one. The new heldout set is called the validation set (or sometimes the development set, or dev set). More specifically, you train multiple models with various hyperparameters on the reduced training set (i.e., the full training set minus the validation set), and you select the model that performs best on the validation set. After this holdout validation process, you train the best model on the full training set (including the validation set), and this gives you the final model. Lastly, you evaluate this final model on the test set to get an estimate of the generalization error.
This solution usually works quite well. However, if the validation set is too small, then model evaluations will be imprecise: you may end up selecting a suboptimal model by mistake. Conversely, if the validation set is too large, then the remaining training set will be much smaller than the full training set. One way to solve this problem is to perform repeated cross-validation, using many small validation sets. Each model is evaluated once per validation set, after it is trained on the rest of the data. By averaging out all the evaluations of a model, we get a much more accurate measure of its performance. However, there is a drawback : the training time is multiplied by the number of validation sets.
Data Mismatch
In some cases, it is easy to get a large amount of data for training, but it is not perfectly representative of the data that will be used in production. In this case, the most important rule to remember is that the validation set and the test must be as representative as possible of the data you expect to use in production. One solution is to hold out part of the training set in yet another set that Andrew Ng calls the train-dev set. After the model is trained (on the training set, not on the train-dev set), you can evaluate it on the train-dev set : if it performs well, then the model is not overfitting the training set, so if performs poorly on the validation set, the problem must come from the data mismatch.
No Free Lunch Theoram
In a famous 1996 paper, David Wolpert demonstrated that if you make absolutely no assumption about the data, then there is no reason to prefer one model over any other. This is called the No Free Lunch (NFL) theorem. For some datasets the best model is a linear model, while for other datasets it is a neural network. There is no model that is a priori guaranteed to work better (hence the name of the theorem). The only way to know for sure which model is best is to evaluate them all.
Test Your Knowledge
Q1 - How would you define Machine Learning?
Machine learning is about building systems that can learn from data. Learning means getting
better at some task, given some performance measurement.
Q2 - Can you name four types of problems where it shines?
Machine learning is great for :
1. Complex problems for which we have no algorithmic solution.
2. To replace long lists of hand-tuned rules.
3. To build systems that adapt to fluctuating environments.
4. To help humans learn.
Q3 - What is a labeled training set?
It is a training set that contains the desired solution for each instance.
Q4 - What are the two most common supervised tasks?
The two most common supervised tasks are :
1. Regression
2. Classification
Q5 - Can you name four common unsupervised tasks?
The four common unsupervised tasks are :
1. Clustering
2. Visualization
3. Dimensionality reduction
4. Association rule learning
Q6 - What type of Machine Learning algorithm would you use to allow a robot to walk in various unknown terrains?
Reinforcement Learning is likely to perform best if we want a robot to learn to walk in
various unknown terrains, since this is typically the type of problem that Reinforcement
Learning tackles. It might be possible to express the problem as a supervised or
semisupervised learning problem, but it would be less natural.
Q7 - What type of algorithm would you use to segment your customers into multiple groups?
If you don't know how to define the groups, than you can use a clustering algorithm to segment
your customers into clusters of similar customers. However, if you know what groups you would
like to have, than you can feed many examples of each group to a classification algorithm,
and it will classify all your customers into these groups.
Q8 - Would you frame the problem of spam detection as a supervised learning problem or an unsupervised learning problem?
Spam detection is a typical supervised learning problem : the algorithm is fed many emails
along with their labels.
Q9 - What is an online learning system?
An online learning system can learn incrementally, as opossed to a batch learning system.
This makes it capable of adapting rapidly to both changing data and autonomous systems,
and of training on very large quantities of data.
Q10 - What is out-of-core learning?
Out-of-core algorithms can handle vast quantities of data that cannot fit in a computer's
main memory. An out-of-core learning algorithm chops the data into mini-batches and uses
online learning techniques to learn from these mini-batches.
Q11 - What type of learning algorithm relies on a similarity measure to make predictions?
An instance-based learning system learns the training data by heart; then, when given a
new instance, it uses a similarity measure to find the most similar learned instances
and uses them to make predictions.
Q12 - What is the difference between a model parameter and a learning algorithm’s hyperparameter?
A model has one or more model parameters that determine what it will predict given a new
instance. A learning algorithm tries to find optimal values for these parameters such
that the model generalizes well to new instances. A hyperparameter is a parameter of the
learning algorithm itself, not of the model.
Q13 - What do model-based learning algorithms search for? What is the most common strategy they use to succeed? How do they make predictions?
Model-based learning algorithms search for an optimal value for the model parameters such
that the model will generalize well to new instances. We usually train such systems by
minimizing a cost function that measures how bad the system is at making predictions on
the training data, plus a penalty for model complexity if the model is regularized. To
make predictions, we feed the new instance's features into the model's prediction
function, using the parameter values found by the learning algorithm.
Q14 - Can you name four of the main challenges in Machine Learning?
Four main challenges in machine learning :
1. Lack of data
2. Poor data quality
3. Non-representative data
4. Uninformative features
Q15 - If your model performs great on the training data but generalizes poorly to new instances, what is happening? Can you name three possible solutions?
If a model performs great on the training data but generalizes poorly to new instances, the
model is likely overfitting the training data. Possible solutions to overfitting are getting
more data, simplifying the model, or reducing the noise in the training data.
Q16 - What is a test set and why would you want to use it?
A test set is used to estimate the generalization error that a model will make on new
instances, before the model is launched in production.
Q17 - What is the purpose of a validation set?
A validation set is used to compare models. It makes it possible to select the best model
and tune the hyperparameters.
Q18 - What is the train-dev set, when do you need it, and how do you use it?
The train-dev set is used when there is a risk of mismatch between the training data and
the data used in the validation and test datasets. The train-dev set is a part of the
training set that's held out. The model is trained on the rest of the training set, and
evaluated on both the train-dev set and the validation set. If the model performs well
on the training set but not on the train-dev set, than the model is likely overfitting
the training set. If it performs well on both the training set and the train-dev set, but
not on the validation set, than there is probably a significant data mismatch between the
training data and the validation + test data, and you should try to improve the training
data make it look more like the validation + test data.
Q19 - What can go wrong if you tune hyperparameters using the test set?
If you tune hyperparameters using the test set, you risk overfitting the test set, and the
generalization error you measure will be optimistic.