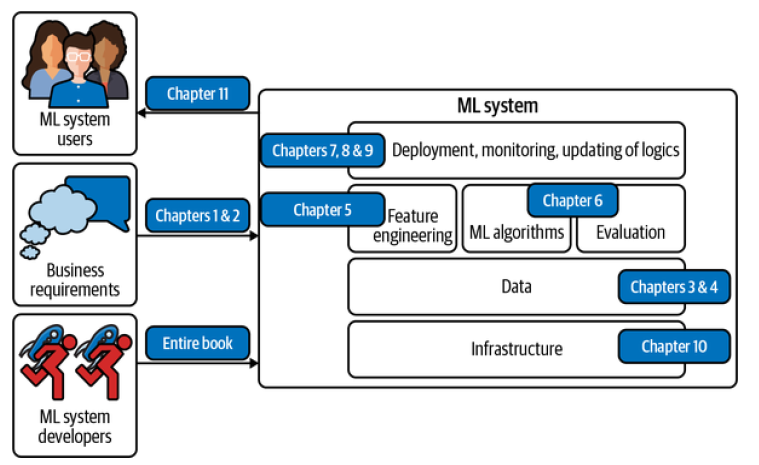
Overview of Machine Learning Systems
In just five years, ML has found its way into almost every aspect of our lives: how we access information, how we communicate, how we work, how we find love. The spread of ML has been so rapid that it’s already hard to imagine life without it. Many people, when they hear “machine learning system,” think of just the ML algorithms being used such as logistic regression or different types of neural networks. However, the algorithm is only a small part of an ML system in production. The system also includes the business requirements that gave birth to the ML project in the first place, the interface where users and developers interact with your system, the data stack, and the logic for developing, monitoring, and updating your models, as well as the infrastructure that enables the delivery of that logic.
When to Use Machine Learning
ML has proven to be a powerful tool for a wide range of problems. ML is not a magic tool that can solve all problems. Even for problems that ML can solve, ML solutions might not be the optimal solutions. To understand what ML can do, let’s examine what ML solutions generally do :
Machine learning is an approach to (1) learn (2) complex patterns from (3) existing data and use these patterns to make (4) predictions on (5) unseen data.
- Learn : A relational database isn’t an ML system because it doesn’t have the capacity to learn. For an ML system to learn, there must be something for it to learn from. In most cases, ML systems learn from data. Once learned, this ML system should be able to predict the price of a new listing given its characteristics.
- Complex patterns : ML solutions are only useful when there are patterns to learn. Sane people don’t invest money into building an ML system to predict the next outcome of a fair die because there’s no pattern in how these outcomes are generated. However, there are patterns in how stocks are priced, and therefore companies have invested billions of dollars in building ML systems to learn those patterns. ML has been very successful with tasks with complex patterns such as object detection and speech recognition.
- Existing data : Because ML learns from data, there must be data for it to learn from. In the zero-shot learning context, it’s possible for an ML system to make good predictions for a task without having been trained on data for that task. However, this ML system was previously trained on data for other tasks, often related to the task in consideration. So even though the system doesn’t require data for the task at hand to learn from, it still requires data to learn.
- Predictions : Compute-intensive problems are one class of problems that have been very successfully reframed as predictive. Instead of computing the exact outcome of a process, which might be even more computationally costly and time-consuming than ML, you can frame the problem as: “What would the outcome of this process look like?” and approximate it using an ML model. The output will be an approximation of the exact output, but often, it’s good enough.
- Unseen data : The patterns your model learns from existing data are only useful if unseen data also share these patterns. In technical terms, it means your unseen data and training data should come from similar distributions. If they don’t, we’ll have a model that performs poorly, which we might be able to find out with monitoring.
- It’s repetitive : Humans are great at few-shot learning: you can show kids a few pictures of cats and most of them will recognize a cat the next time they see one. Despite exciting progress in few-shot learning research, most ML algorithms still require many examples to learn a pattern. When a task is repetitive, each pattern is repeated multiple times, which makes it easier for machines to learn it.
- The cost of wrong predictions is cheap : Unless your ML model’s performance is 100% all the time, which is highly unlikely for any meaningful tasks, your model is going to make mistakes. ML is especially suitable when the cost of a wrong prediction is low. If one prediction mistake can have catastrophic consequences, ML might still be a suitable solution if, on average, the benefits of correct predictions outweigh the cost of wrong predictions.
- It’s at scale : ML solutions often require nontrivial up-front investment on data, compute, infrastructure, and talent, so it’d make sense if we can use these solutions a lot. “At scale” means different things for different tasks, but, in general, it means making a lot of predictions. Examples include sorting through millions of emails a year or predicting which departments thousands of support tickets should be routed to a day.
- The patterns are constantly changing : Cultures change. Tastes change. Technologies change. What’s trendy today might be old news tomorrow. If your problem involves one or more constantly changing patterns, hardcoded solutions such as handwritten rules can become outdated quickly. Because ML learns from data, you can update your ML model with new data without having to figure out how the data has changed.
However, even if ML can’t solve your problem, it might be possible to break your problem into smaller components, and use ML to solve some of them. For example, if you can’t build a chatbot to answer all your customers’ queries, it might be possible to build an ML model to predict whether a query matches one of the frequently asked questions. If yes, direct the customer to the answer. If not, direct them to customer service.
Machine Learning Use Cases
With the explosion of information and services, it would have been very challenging for us to find what we want without the help of ML, manifested in either a search engine or a recommender system. If you have a smartphone, ML is likely already assisting you in many of your daily activities. Typing on your phone is made easier with predictive typing, an ML system that gives you suggestions on what you might want to say next. An ML system might run in your photo editing app to suggest how best to enhance your photos. ML is increasingly present in our homes with smart personal assistants such as Alexa and Google Assistant. Smart security cameras can let you know when your pets leave home or if you have an uninvited guest.
Enterprise ML applications tend to have vastly different requirements and considerations from consumer applications. There are many exceptions, but for most cases, enterprise applications might have stricter accuracy requirements but be more forgiving with latency requirements. For example, improving a speech recognition system’s accuracy from 95% to 95.5% might not be noticeable to most consumers, but improving a resource allocation system’s efficiency by just 0.1% can help a corporation like Google or General Motors save millions of dollars.
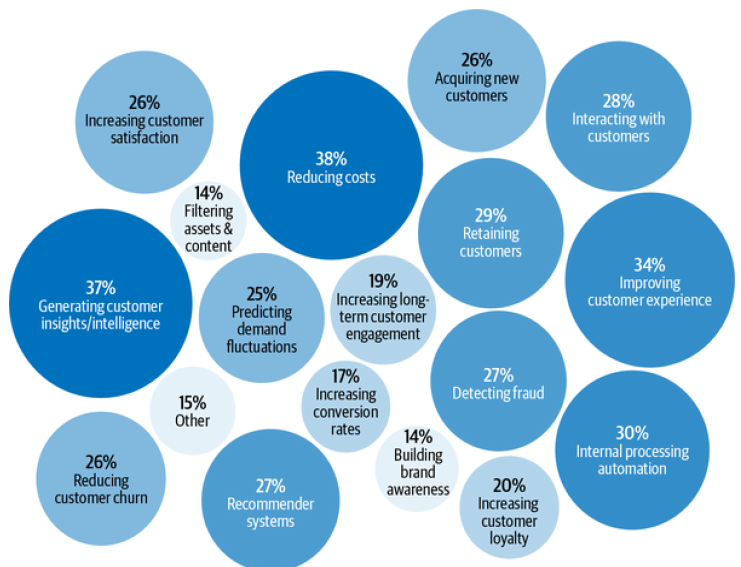
Fraud detection is among the oldest applications of ML in the enterprise world. If your product or service involves transactions of any value, it’ll be susceptible to fraud. By leveraging ML solutions for anomaly detection, you can have systems that learn from historical fraud transactions and predict whether a future transaction is fraudulent. A set of ML use cases that has generated much excitement recently is in health care. There are ML systems that can detect skin cancer and diagnose diabetes. Even though many health-care applications are geared toward consumers, because of their strict requirements with accuracy and privacy, they are usually provided through a health-care provider such as a hospital or used to assist doctors in providing diagnosis.
Machine Learning in Research Versus in Production
As ML usage in the industry is still fairly new, most people with ML expertise have gained it through academia: taking courses, doing research, reading academic papers. If that describes your background, it might be a steep learning curve for you to understand the challenges of deploying ML systems in the wild and navigate an overwhelming set of solutions to these challenges. ML in production is very different from ML in research.
| Research | Production | |
|---|---|---|
| Requirements | State-of-the-art model performance on benchmark datasets | Different stakeholders have different requirements |
| Computational priority | Fast training, high throughput | Fast inference, low latency |
| Data | Static | Constantly shifting |
| Fairness | Often not a focus | Must be considered |
| Interpretability | Often not a focus | Must be considered |
Different stakeholders and requirements
People involved in a research and leaderboard project often align on one single objective. The most common objective is model performance- develop a model that achieves the state-of-the-art results on benchmark datasets. There are many stakeholders involved in bringing an ML system into production. Each stakeholder has their own requirements. Having different, often conflicting, requirements can make it difficult to design, develop, and select an ML model that satisfies all the requirements.
When developing an ML project, it’s important for ML engineers to understand requirements from all stakeholders involved and how strict these requirements are. For example, if being able to return recommendations within 100 milliseconds is a must-have requirement—the company finds that if your model takes over 100 milliseconds to recommend restaurants, 10% of users would lose patience and close the app.
Production having different requirements from research is one of the reasons why successful research projects might not always be used in production.
Computational priorities
When designing an ML system, people who haven’t deployed an ML system often make the mistake of focusing too much on the model development part and not enough on the model deployment and maintenance part. During the model development process, you might train many different models, and each model does multiple passes over the training data. Each trained model then generates predictions on the validation data once to report the scores. The validation data is usually much smaller than the training data. During model development, training is the bottleneck. Once the model has been deployed, however, its job is to generate predictions, so inference is the bottleneck. Research usually prioritizes fast training, whereas production usually prioritizes fast inference.
To reduce latency in production, you might have to reduce the number of queries you can process on the same hardware at a time. If your hardware is capable of processing many more queries at a time, using it to process fewer queries means underutilizing your hardware, increasing the cost of processing each query. When thinking about latency, it’s important to keep in mind that latency is not an individual number but a distribution. It’s usually better to think in percentiles, as they tell you something about a certain percentage of your requests. The most common percentile is the 50th percentile, abbreviated as p50. It’s also known as the median. If the median is 100 ms, half of the requests take longer than 100 ms, and half of the requests take less than 100 ms.
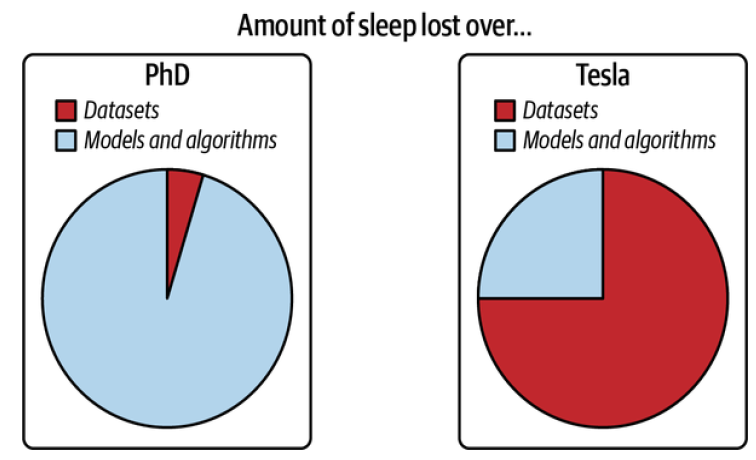
Data
During the research phase, the datasets you work with are often clean and well-formatted, freeing you to focus on developing models. They are static by nature so that the community can use them to benchmark new architectures and techniques.
In production, data, if available, is a lot more messy. It’s noisy, possibly unstructured, constantly shifting. It’s likely biased, and you likely don’t know how it’s biased. Labels, if there are any, might be sparse, imbalanced, or incorrect. Changing project or business requirements might require updating some or all of your existing labels.
Fairness
During the research phase, a model is not yet used on people, so it’s easy for researchers to put off fairness as an afterthought: “Let’s try to get state of the art first and worry about fairness when we get to production.” When it gets to production, it’s too late. You or someone in your life might already be a victim of biased mathematical algorithms without knowing it. Your loan application might be rejected because the ML algorithm picks on your zip code, which embodies biases about one’s socioeconomic background.
ML algorithms don’t predict the future, but encode the past, thus perpetuating the biases in the data and more. When ML algorithms are deployed at scale, they can discriminate against people at scale. If a human operator might only make sweeping judgments about a few individuals at a time, an ML algorithm can make sweeping judgments about millions in split seconds.
Interpretability
While most of us are comfortable with using a microwave without understanding how it works, many don’t feel the same way about AI yet, especially if that AI makes important decisions about their lives. Since most ML research is still evaluated on a single objective, model performance, researchers aren’t incentivized to work on model interpretability. However, interpretability isn’t just optional for most ML use cases in the industry, but a requirement.
First, interpretability is important for users, both business leaders and end users, to understand why a decision is made so that they can trust a model and detect potential biases mentioned previously. Second, it’s important for developers to be able to debug and improve a model.
Machine Learning systems VS Traditional Software
Since ML is part of software engineering (SWE), and software has been successfully used in production for more than half a century, some might wonder why we don’t just take tried-and-true best practices in software engineering and apply them to ML.
However, many challenges are unique to ML applications and require their own tools. In SWE, there’s an underlying assumption that code and data are separated. On the contrary, ML systems are part code, part data, and part artifacts created from the two. The trend in the last decade shows that applications developed with the most/best data win. Instead of focusing on improving ML algorithms, most companies will focus on improving their data.
In traditional SWE, you only need to focus on testing and versioning your code. With ML, we have to test and version our data too, and that’s the hard part. How to version large datasets? How to know if a data sample is good or bad for your system? Not all data samples are equal—some are more valuable to your model than others.